
- Agosto 22, 2023
- Posted by: vtsolutions
- Categories: Big Data & Analytics, News
A cura di Antonio Rovitti – Data Architect
Il mondo dei Big Data è un’area di competenza che sta destando tantissimo interesse, in quanto la mole dei dati nel corso degli ultimi anni è aumentata esponenzialmente e le aziende mostrano sempre più consapevolezza del valore che si può ottenere dall’analisi di queste grandi quantità di dati, consentendo di misurare continuamente i principali KPI (Key Performance Indicators), monitorare l’andamento del proprio business, razionalizzare ed ottimizzare risorse e costi, supportare le decisioni e indirizzare le strategie commerciali.
Giusto per dare una misura della crescita, a livello di volumi, nel 2020 sono stati creati circa 64,2 ZB (Zettabyte) di dati, nel 2022 si è passati a 79 ZB e nel 2025 si arriverà a toccare il tetto di 180 ZB, quindi un aumento di quasi il 300% in 5 anni;
come volume d’affari nel 2022 sul mercato italiano ha raggiunto i 2,4 miliardi di Euro, con ultimo incremento annuo pari al 20% (vedi immagine a seguire).

fonte: Osservatorio Big data and Business analytics del Politecnico di Milano
VT Solutions & Consulting da anni lavora nel mondo Data & Analytics al fianco dei propri clienti, la maggior parte dei quali “Data driven” companies ovvero realtà industriali che si fanno supportare costantemente nelle strategie di business dall’analisi dei dati.
VT Solutions sta puntando su questa area di competenza, oramai divenuta uno dei “Pillar” centrali dell’azienda, avendo nel proprio staff tecnico figure professionali certificate (Senior Data Engineers, Data and Solution Architects, Data Analyst, Data Scientist..) con comprovate esperienze sul campo, avendo partecipato anche a progetti di respiro internazionale.
Professionalità consolidate anche grazie alla progettazione e sviluppo di una propria Big Data platform sia su Public Cloud (Azure, Google, AWS), su Hybrid Cloud ed Edge computing e che sta rappresentando un abilitatore fondamentale per poter costruire “on top” soluzioni di Reporting/BI, Artificial Intelligence e Machine Learning.
I sistemi transazionali standard (OLTP con database relazionali) non erano in grado di gestire in maniera performante in termini di tempi e costi, queste grandi quantità di dati oltre che la loro varietà, non essendo progettati per il processamento e la persistenza dei dati in modo efficiente e distribuito; in particolare i database NoSQL si prestano bene ad immagazzinare grandi volumi di dati, perché scalano orizzontalmente anche con dati non strutturati e denormalizzati, mentre i database SQL scalano solo verticalmente e con dati strutturati e normalizzati.
Una Big Data Platform è progettata per acquisire, gestire, archiviare e fornire supporto analitico per grandi set di dati eterogenei (strutturati o semi-strutturati o non-strutturati), provenienti da differenti sorgenti (siano essi residenti on-prem o in cloud) e si basa su una architettura scalabile, performante, sicura e resiliente sia per i servizi che si occupano del processamento dati che dal punto di vista del data storage.
In una Big Data platform un tipico flusso dati (o pipeline) viene gestito nel seguente modo:
i dati vengono prima pre-processati ed “ingeriti” (in modalità “batch” , “streaming/real-time” o “near real- time”), poi vengono persistiti e propagati in diverse “zone” della Big Data platform (landing, raw/bronze, curated/silver, serving/gold) con gli opportuni meccanismi di validazione e trasformazione, infine vengono aggregati in “viste” e datamart, al fine di fornire ai consumatori finali funzionalità di reportistica e dashboard. La freschezza del dato in fase di “data visualization” dipenderà dalla latenza di propagazione del flusso, e sarà sicuramente influenzata dai requisiti funzionali e dal caso d’uso, ma che si potrà modulare attraverso varie tecniche e framework di design. Ovviamente più dati di buona qualità si hanno a disposizione, migliori saranno i risultati delle analisi.
È necessario quindi adottare un’ architettura Big Data nei seguenti scenari, ovvero quando occorre:
- lavorare con volumi di dati troppo grandi per un sistema transazionale;
- lavorare con flussi di dati eterogenei, in real-time, near real-time o batch;
- trasformare dati eterogenei, non strutturati e non relazionati per consentire una successiva analisi;
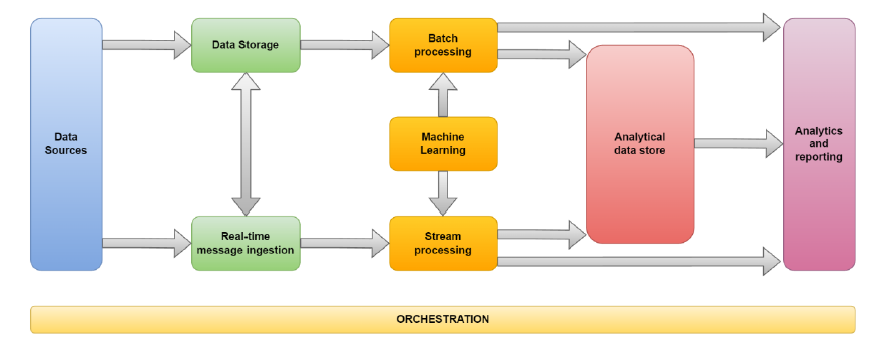
Il diagramma seguente illustra i componenti logici, successivamente dettagliati, di una classica Architettura per Big Data:
Data Source: una o più origine di dati eterogenei tipo: database relazionali, file di log, stream IoT, immagini;
Data Storage: dati tendenzialmente inseriti in un archivio di file distribuito capace di contenere volumi elevati di file in vari formati;
Batch Processing: avendo a che fare con grandi set di dati spesso bisogna elaborare i dati con processi batch a lunga esecuzione per filtrare, elaborare ed aggregare i dati ai fini dell’analisi;
Real-time message ingestion: se la soluzione prevede stream real-time bisogna gestire acquisizione ed archiviazione di questi flussi solitamente effettuata tramite stream buffering;
Stream processing: una volta acquisito lo stream real time è necessario elaborarlo, filtrarlo ed aggregarlo per renderlo fruibile dall’analisi scrivendoli su un sink di output;
Machine learning: i dati preparati per l’analisi, da flusso batch e/o real time, possono andare in pasto ad algoritmi di machine learning al fine di creare modelli predittivi o di classificazione;
Analytical data store: i dati preparati per le analisi vengono storati, in un formato strutturato su cui è possibile eseguire query, su un archivio dati analitico. Tale archivio può essere un data warehouse relazionale o in alternativa tramite una tecnologia NoSQL tipo HBase, Hive, Cassandra, Mongo DB… ;
Analytics and reporting: obiettivo finale di una qualsiasi soluzione Big Data è fornire, tramite analisi e report, informazioni specifiche sui dati. Per consentire agli utenti di analizzare in modo efficiente questi volumi di dati, l’architettura può fornire un livello di modellazione dati (cubi OLAP multidimensionali) oppure tecnologie di reporting/business intelligence quali Power BI;
Orchestration: le soluzioni per Big Data, spesso, consistono in operazioni ripetute. Sono flussi di lavoro che manipolano i dati provenienti da più origini (tramite job ETL o ELT) e li caricano in archivi di dati analitici o direttamente all’interno di un report. Questi flussi possono essere automatizzati con l’ausilio di tecnologie di orchestrazione come Azure Data Factory, Databricks, Talend, Pentaho.
Il diagramma seguente illustra i data layer standard di un‘ Architettura per Big Data:
